Why Geo RCTs Beat User-Level Tests for Ad Sales Measurement

Don’t mistake precision for accuracy
Measuring advertising's true effect on sales is one of the most consequential and contested problems in marketing. Randomized controlled trials (RCTs) are the right tool for it. But not all RCTs are created equal, and the choice of experimental unit, user-level versus geographic regions, has profound implications for what you can actually learn and trust.
The most common objection to geo RCTs is that DMAs are few in number (only 210 in the US) and vary widely in population, wealth, and sales rates. This concern is real but solvable. We address it in detail in our whitepaper How to Design a Geographic Randomized Controlled Trial, but the short answer is that we advocate a multi-armed stepped design we call Rolling Thunder, which naturally improves balance and statistical power. Techniques such as covariate-constrained re-randomization can be layered on for additional assurance.
Let me be clear about what I mean by a geo test. Matched market tests and synthetic control methods are quasi-experiments, not geo RCTs. I advocate full random assignment across all available DMAs, using your own first-party transaction data as the outcome measure. That is a cluster randomized trial (CRT), a methodologically robust type of RCT.
The ITT Advantage
Geo tests are Intent-to-Treat (ITT) experiments on an unfiltered audience. Every person living in a treatment DMA is eligible to be exposed to the advertising (or not, in a suppression test), and you measure what happens to total sales in that geography. That is the question the CFO cares about: how a given channel, vendor, or tactic impacts the bottom line. It is also how market mix modeling wants the data: a clean, national-scope sales lift signal to calibrate media coefficients.
Most user-level tests, by contrast, are Treatment on Treated designs. Ghost ad tests, platform holdouts, PSA-style placebo tests, and clean room lift studies all measure lift among users the platform could identify and target, within the subset whose exposures and outcomes can be observed and matched. That is a fundamentally different question from ITT. It asks: among the in-market users this platform was able to reach, did the ones who saw our ad buy more?
That is a narrower question, on a more selected and already purchase-prone sample. And even when the answer is yes, the incremental effect is confined to the reached audience, which may be a small slice of total sales. Marketing celebrates a statistically significant lift while the finance department scratches its head wondering why they don't see it in the P&L. Geo tests, by measuring total sales across entire geographies, produce a result that maps directly onto the numbers the CFO is already looking at.
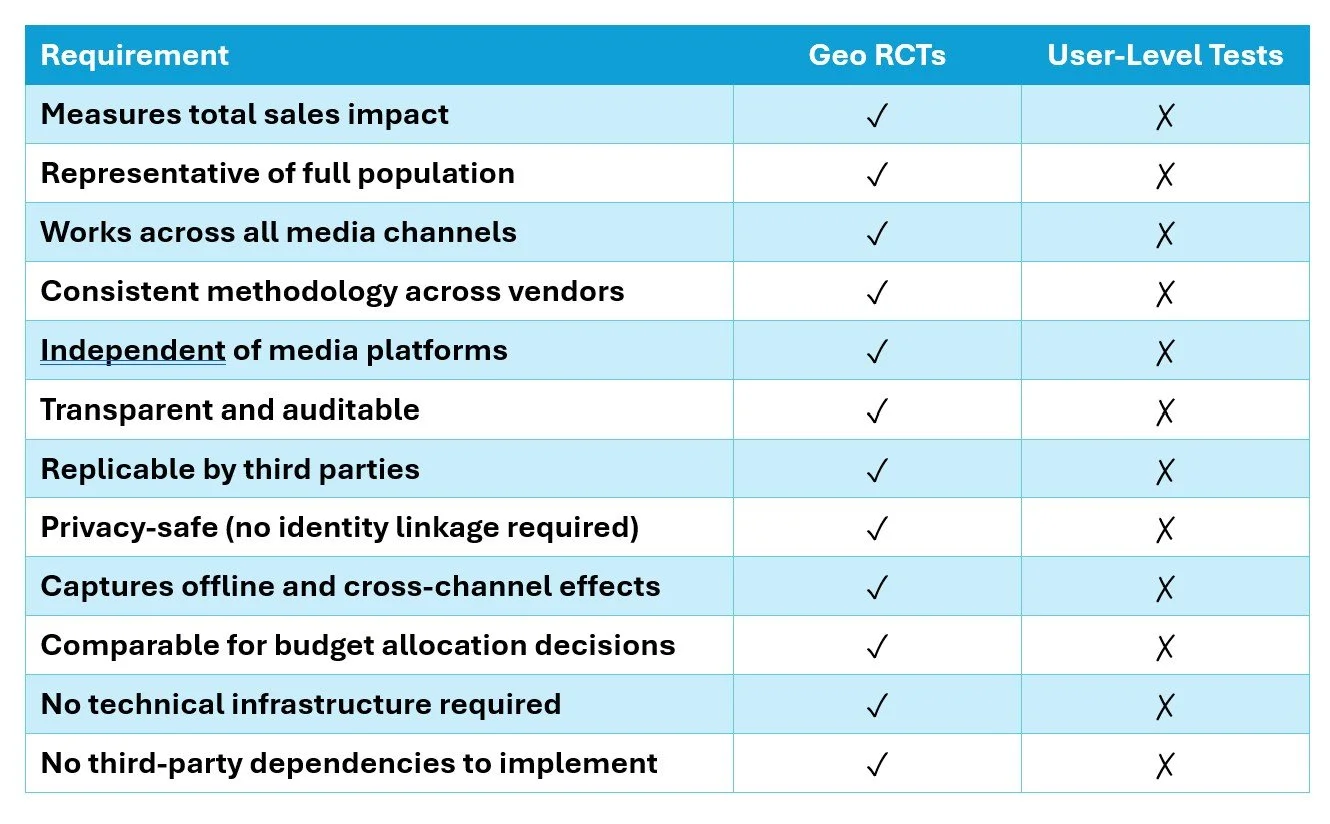
Large-scale geographic randomized experiments check every box of what advertisers want in simple, fair ROI measurement
The Match Rate Problem Is Structural, Not Incidental
Match rates between media-exposed audiences and sales data commonly run 50% or worse (typically between 29% and 63%, says Google). That is not a solvable engineering problem. It is an inherent consequence of how identity works in a privacy-constrained world.
Apple's ATT framework has made large shares of iOS users essentially dark. Users maintain multiple email addresses. Cookie graphs have degraded. Login signals are incomplete outside of walled gardens. The resulting non-matches are not missing at random; they are systematically biased. The unmatched population skews younger, more mobile-first, more privacy-conscious, and more likely to be new-to-category. These are prized customer attributes, precisely the users you most want to understand.
When your lift estimate is based on the matched half of your audience, and that half is systematically different from the unmatched half, you cannot soundly generalize the result to your total population. And since advertising's total lift on sales is typically well under 10%, the noise and bias introduced by a non-random 50% sample can easily overwhelm the signal.
Clean rooms don’t change this. They govern how data is joined and shared, but they don’t increase match rates to anything close to complete coverage, nor do they make the unmatched population representative. The underlying bias remains.
Geo tests sidestep this entirely. Geographic boundaries are stable, well-defined, and match to postal codes already sitting in your transaction data. No joins. No device graphs. No clean rooms. No PII.
Platform-Administered Tests Have a Conflict of Interest
When a media company runs your incrementality test, they control the randomization, the exposure data, and the reporting. It's the classic vendor-grading-its-own-homework problem. This is not an accusation of bad faith. It is a structural problem that no amount of good faith resolves.
As I wrote in The First Principle of Honest Advertising Measurement Is Independence from the Media, sound measurement requires independence in the independent variable. Geo tests give you that. You provide a randomization scheme. You instruct the media company to run in those geographies and not others. You read the outcome from your own transaction data. The media company never touches the outcome measurement.
The Cross-Channel Comparability Problem
User-level test designs are not portable across the media mix. The mechanics depend entirely on the strength of a given platform's user graph, its willingness to support holdouts, and its data-sharing infrastructure. A ghost ad test on search, a clean room lift study on social, and a view-through match on programmatic are three different methodologies measuring three different things in three different conditions. You cannot compare them.
This is compounded by the fact that many of these approaches only observe a subset of outcomes, often limited to digitally trackable conversions, while a meaningful share of sales may occur in other channels (retail, call center, cross-retailer), outside the measurement frame.
Geo tests work the same way for every channel: search, social, retail media, programmatic, linear TV, radio, out of home. The randomization unit (geography), the treatment mechanism (run here, don't run there), and the outcome measurement (your own sales data) are identical across all of them. That is what makes geo tests uniquely suited to the budget allocation question: what is the best use of my next dollar across all channels?
User-level tests, administered by platforms within their own targeting conditions, answer a narrower question: among the users this platform reached in this campaign, did the ad work? Those are not equivalent questions, and conflating them is one of the most expensive measurement mistakes in the industry.
The Targeting Bias Problem
Platforms are expert at harvesting demand. Search and social algorithms identify users already exhibiting signals of purchase intent: behavioral, contextual, lookalike. These users have often already been primed by TV, out-of-home, and other upper-funnel channels. When a platform-run RCT shows that exposed users convert at twice the rate of the control group, it is measuring the incremental value of that final touchpoint on an already-primed, high-intent audience. That is not the same as measuring the channel's contribution to generating demand in the first place.
This is why platform lift studies reliably show impressive numbers that don't survive scrutiny when compared to the accounting P&L or to measurements by geo tests. The lift effect by the platform may be real: within the selected audience, the ad did something. But it overstates the channel's independent contribution to sales and systematically undervalues upper-funnel media that does the priming work but doesn't receive credit in the attribution.
First-Party Seeds Preclude New Customer Measurement
Some advertisers try to regain control by seeding user-level tests with their own first-party customer data. This solves the independence problem but creates a new one: you can't measure new customer acquisition if your randomization universe is your existing customer file. For most brands, new customer acquisition is the primary objective of advertising. A measurement approach that requires you to exclude new customers from the frame is not fit for that purpose.
The Operational Overhead
User-level tests require third-party identity resolution, clean room infrastructure, legal agreements, data transfer protocols, and ongoing engineering maintenance. Each adds cost, latency, and opportunity for error. The clean room ecosystem has matured, but it remains complex, expensive, and dependent on a set of intermediaries who each introduce their own opacity.
Geo tests require none of this. You give your media partners a list of geographies. You read your own sales data. The analysis is transparent, replicable, and auditable by anyone with access to your transaction data and a spreadsheet.
Equal-Sized Test and Control Groups
User-level experiments are often constrained in how they allocate traffic between treatment and control. In practice, control groups are frequently kept small, on the order of 10 to 20 percent, to avoid disrupting campaign delivery. As experimentation expert Ron Kohavi has pointed out, unequal splits can interact with real-world systems in ways that violate assumptions, from caching effects to cookie churn to different convergence rates. A/A tests with unequal allocation often fail for this reason. The result is not just reduced statistical power, but reduced trust in the experiment itself.
Geo designs can avoid this constraint. Multi-armed approaches such as Rolling Thunder can use multiple, equal-sized, randomly assigned arms and can incorporate more than one control group, allowing for balanced allocation and built-in A/A validation. Importantly, this does not require holding out 50 percent of the country. With multiple arms and a stepped design, you can achieve balanced test and control groups while maintaining national coverage, a point I discussed in The Cost of Testing vs. the Cost of Being Wrong.
Geo Tests Are the Simple, Independent Standard Advertisers Have Been Asking For
For years, advertisers have asked for a measurement approach that is simple, transparent, consistent across channels, and independent of the platforms being measured. Something that does not rely on identity resolution, does not require complex infrastructure, and produces results that can be trusted and acted on.
Geo RCTs meet those requirements. User-level tests, in most cases, do not.
User-level tests still have a role. They are useful for creative and audience diagnostics within a platform, and for testing messaging among existing customers. But for the primary question, does this channel drive incremental sales, and how does it compare across the media mix, geo RCTs provide the more reliable answer.
The industry’s obsession with user-level measurement was never really about better science. It was about the internet’s original promise of 1:1 marketing precision, a promise that was always overstated and is now, in a privacy-constrained world, largely undeliverable. Don’t mistake precision for accuracy. Identity is not necessary for accurate measurement.
Cluster randomized trials using geographic units have been the workhorse of causal inference in public health, economics, and policy research for decades. They work because randomization, not identity resolution, is what eliminates confounding. The platforms built identity infrastructure because it served their business models. Advertisers adopted it because it felt rigorous. It isn’t.
Large-scale geo RCTs, reading outcomes from your own transaction data, remain the most reliable method we have for knowing what advertising actually does to sales.